A easy to use API to store outputs from forward/backward hooks in Pytorch
Francesco Saverio Zuppichini
pip install git+https://github.com/FrancescoSaverioZuppichini/PytorchModuleStorage.git
You have a model, e.g. vgg19 and you want to store the features in the third layer given an input x.
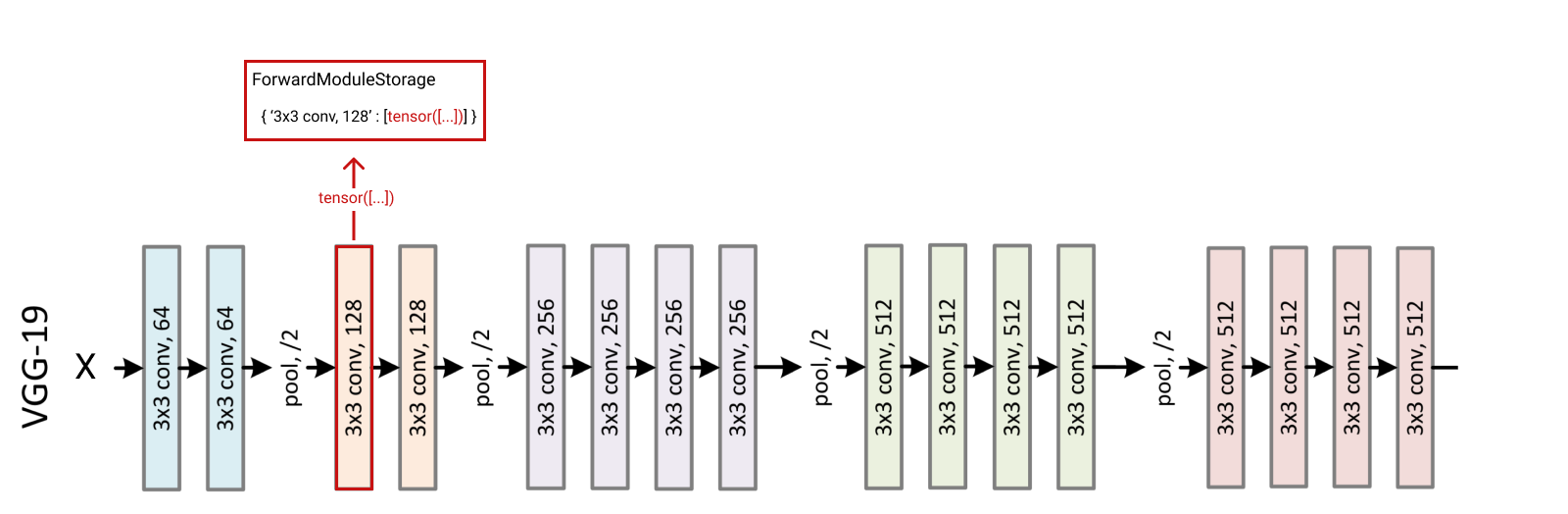
First, we need a model. We will load vgg19 from torchvision.models. Then, we create a random input x
import torchfrom torchvision.models import vgg19from PytorchStorage import ForwardModuleStoragedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')cnn = vgg19(False).to(device).eval()
Then, we define a ForwardModuleStorage instance by passing the model and the list of layer we are interested on.
storage = ForwardModuleStorage(cnn, [cnn.features[3]])
Finally, we can pass a input to the storage.
x = torch.rand(1,3,224,224).to(device) # random input, this can be an imagestorage(x) # pass the input to the storagestorage[cnn.features[3]][0] # the features can be accessed by passing the layer as a key
tensor([[[[0.0815, 0.0000, 0.0136, ..., 0.0435, 0.0058, 0.0584],[0.1270, 0.0873, 0.0800, ..., 0.0910, 0.0808, 0.0875],[0.0172, 0.0095, 0.1667, ..., 0.2503, 0.0938, 0.1044],...,[0.0000, 0.0181, 0.0950, ..., 0.1760, 0.0261, 0.0092],[0.0533, 0.0043, 0.0625, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0776, 0.1942, 0.2467, ..., 0.1669, 0.0778, 0.0969],[0.1714, 0.1516, 0.3037, ..., 0.1950, 0.0428, 0.0892],[0.1219, 0.2611, 0.2902, ..., 0.1964, 0.2083, 0.2422],...,[0.1813, 0.1193, 0.2079, ..., 0.3328, 0.4176, 0.2015],[0.0870, 0.2522, 0.1454, ..., 0.2726, 0.1916, 0.2314],[0.0250, 0.1256, 0.1301, ..., 0.1425, 0.1691, 0.0775]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.1044],[0.0000, 0.0202, 0.0000, ..., 0.0000, 0.0873, 0.0908],[0.0000, 0.0000, 0.0000, ..., 0.0683, 0.0053, 0.1209],...,[0.0000, 0.0000, 0.0818, ..., 0.0000, 0.0000, 0.1722],[0.0000, 0.0493, 0.0501, ..., 0.0112, 0.0000, 0.0864],[0.0000, 0.1314, 0.0904, ..., 0.1500, 0.0628, 0.2383]],...,[[0.0000, 0.0915, 0.1819, ..., 0.1442, 0.0499, 0.0346],[0.0000, 0.0000, 0.0750, ..., 0.1607, 0.0883, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.1648, 0.0250],...,[0.0000, 0.0000, 0.1259, ..., 0.1193, 0.0573, 0.0096],[0.0000, 0.0472, 0.0000, ..., 0.0000, 0.0467, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0000, 0.0000, 0.0154, ..., 0.0080, 0.0000, 0.0000],[0.0347, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.1283, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],...,[0.0510, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0130, 0.0165, 0.0000, ..., 0.0302, 0.0000, 0.0000]],[[0.0000, 0.0499, 0.0000, ..., 0.0221, 0.0180, 0.0000],[0.0730, 0.0000, 0.0925, ..., 0.1378, 0.0475, 0.0000],[0.0000, 0.0677, 0.0000, ..., 0.0000, 0.0070, 0.0000],...,[0.0712, 0.0431, 0.0000, ..., 0.0420, 0.0116, 0.0086],[0.0000, 0.1240, 0.0121, ..., 0.2387, 0.0294, 0.0413],[0.0223, 0.0691, 0.0000, ..., 0.0000, 0.0000, 0.0000]]]],grad_fn=<ReluBackward1>)
The storage keeps an internal state (storage.state) where we can use the layers as key to access the stored value.
You can pass a list of layers and then access the stored outputs
storage = ForwardModuleStorage(cnn, [cnn.features[3], cnn.features[5]])x = torch.rand(1,3,224,224).to(device) # random input, this can be an imagestorage(x) # pass the input to the storageprint(storage[cnn.features[3]][0].shape)print(storage[cnn.features[5]][0].shape)
torch.Size([1, 64, 224, 224])torch.Size([1, 128, 112, 112])
You can also pass multiple inputs, they will be stored using the call order
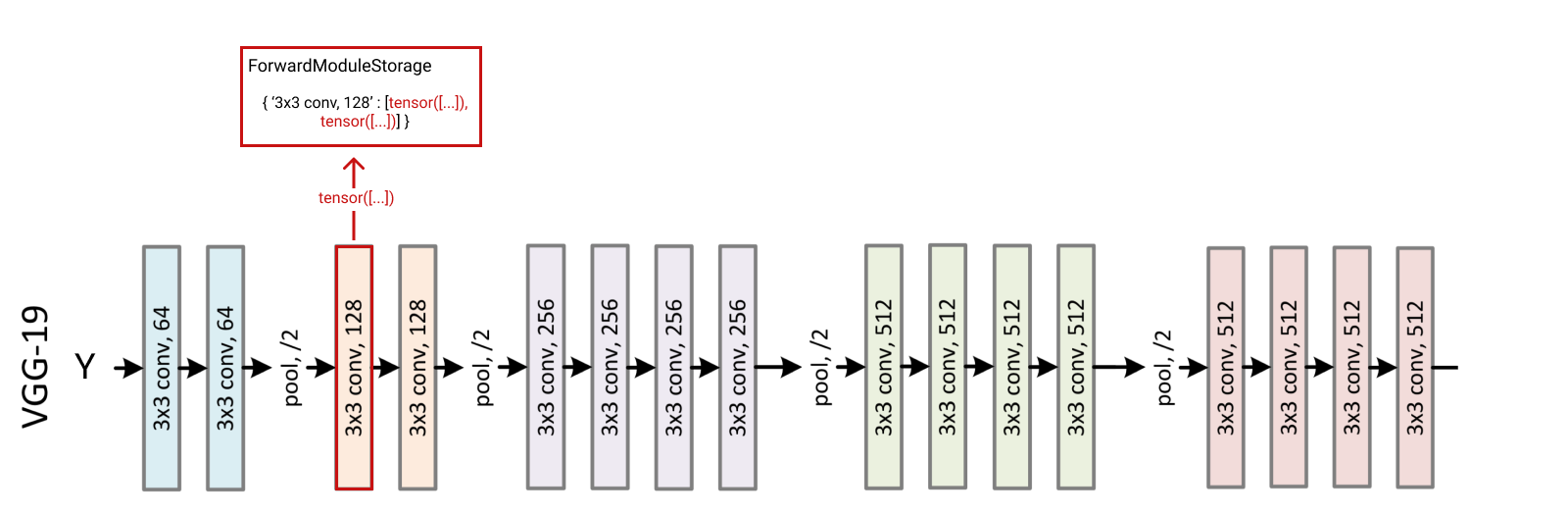
storage = ForwardModuleStorage(cnn, [cnn.features[3]])x = torch.rand(1,3,224,224).to(device) # random input, this can be an imagey = torch.rand(1,3,224,224).to(device) # random input, this can be an imagestorage([x, y]) # pass the inputs to the storageprint(storage[cnn.features[3]][0].shape) # xprint(storage[cnn.features[3]][1].shape) # y
torch.Size([1, 64, 224, 224])torch.Size([1, 64, 224, 224])
Image we want to run x on a set of layers and y on an other, this can be done by specify a dictionary of `{ NAME: [layers…], …}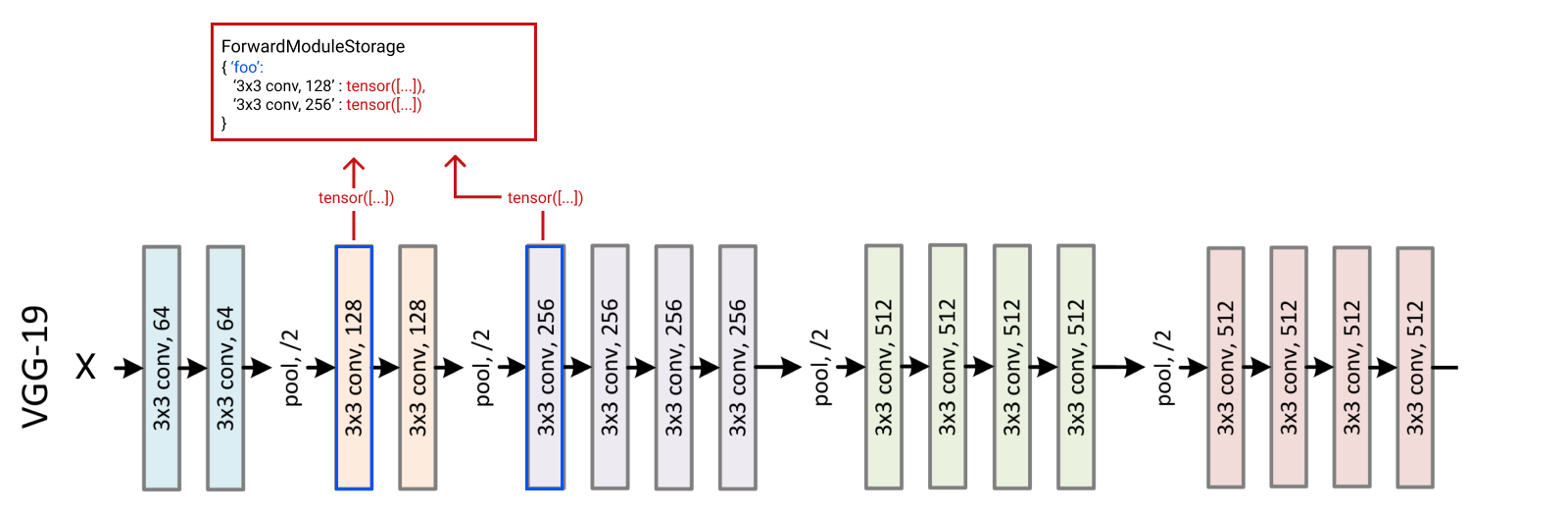
storage = ForwardModuleStorage(cnn, {'style' : [cnn.features[5]], 'content' : [cnn.features[5], cnn.features[10]]})storage(x, 'style') # we run x only on the 'style' layersstorage(y, 'content') # we run y only on the 'content' layersprint(storage['style'])print(storage['style'][cnn.features[5]])
MutipleKeysDict([(Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)), tensor([[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0383, 0.0042, ..., 0.0852, 0.0246, 0.1101],[0.0000, 0.0000, 0.1106, ..., 0.0000, 0.0107, 0.0487],...,[0.0085, 0.0809, 0.0000, ..., 0.0000, 0.0012, 0.0018],[0.0000, 0.0817, 0.1753, ..., 0.0000, 0.0000, 0.0701],[0.0000, 0.1445, 0.1105, ..., 0.2428, 0.0418, 0.0803]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],...,[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0400, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0731, 0.0316, ..., 0.0673, 0.0000, 0.0383],[0.0000, 0.0288, 0.0000, ..., 0.0499, 0.0000, 0.0573],...,[0.0000, 0.0128, 0.0744, ..., 0.1250, 0.0000, 0.0023],[0.0000, 0.0000, 0.0000, ..., 0.0353, 0.0000, 0.0000],[0.0093, 0.1436, 0.1009, ..., 0.2187, 0.0988, 0.0693]],...,[[0.1177, 0.0370, 0.2002, ..., 0.1878, 0.1076, 0.0000],[0.1045, 0.0090, 0.0000, ..., 0.0705, 0.0000, 0.0000],[0.1074, 0.1208, 0.0000, ..., 0.1038, 0.1378, 0.0000],...,[0.0634, 0.0234, 0.0610, ..., 0.0955, 0.0977, 0.0000],[0.1097, 0.0563, 0.0000, ..., 0.0797, 0.0424, 0.0000],[0.0090, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0254],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],...,[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0690, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.1769, 0.0128, 0.1329, ..., 0.0733, 0.1435, 0.0000],[0.1478, 0.0476, 0.0000, ..., 0.0192, 0.0000, 0.0000],...,[0.2258, 0.0908, 0.0621, ..., 0.1120, 0.0678, 0.0000],[0.1161, 0.0625, 0.0694, ..., 0.0365, 0.0000, 0.0000],[0.1360, 0.0890, 0.1442, ..., 0.1679, 0.1336, 0.0432]]]],grad_fn=<ReluBackward1>))])tensor([[[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0383, 0.0042, ..., 0.0852, 0.0246, 0.1101],[0.0000, 0.0000, 0.1106, ..., 0.0000, 0.0107, 0.0487],...,[0.0085, 0.0809, 0.0000, ..., 0.0000, 0.0012, 0.0018],[0.0000, 0.0817, 0.1753, ..., 0.0000, 0.0000, 0.0701],[0.0000, 0.1445, 0.1105, ..., 0.2428, 0.0418, 0.0803]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],...,[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0400, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0731, 0.0316, ..., 0.0673, 0.0000, 0.0383],[0.0000, 0.0288, 0.0000, ..., 0.0499, 0.0000, 0.0573],...,[0.0000, 0.0128, 0.0744, ..., 0.1250, 0.0000, 0.0023],[0.0000, 0.0000, 0.0000, ..., 0.0353, 0.0000, 0.0000],[0.0093, 0.1436, 0.1009, ..., 0.2187, 0.0988, 0.0693]],...,[[0.1177, 0.0370, 0.2002, ..., 0.1878, 0.1076, 0.0000],[0.1045, 0.0090, 0.0000, ..., 0.0705, 0.0000, 0.0000],[0.1074, 0.1208, 0.0000, ..., 0.1038, 0.1378, 0.0000],...,[0.0634, 0.0234, 0.0610, ..., 0.0955, 0.0977, 0.0000],[0.1097, 0.0563, 0.0000, ..., 0.0797, 0.0424, 0.0000],[0.0090, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0254],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],...,[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000]],[[0.0690, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],[0.1769, 0.0128, 0.1329, ..., 0.0733, 0.1435, 0.0000],[0.1478, 0.0476, 0.0000, ..., 0.0192, 0.0000, 0.0000],...,[0.2258, 0.0908, 0.0621, ..., 0.1120, 0.0678, 0.0000],[0.1161, 0.0625, 0.0694, ..., 0.0365, 0.0000, 0.0000],[0.1360, 0.0890, 0.1442, ..., 0.1679, 0.1336, 0.0432]]]],grad_fn=<ReluBackward1>)
You can also store gradients by using BackwardModuleStorage
from PytorchStorage import BackwardModuleStorage
import torch.nn as nn# we don't need the module, just the layersstorage = BackwardModuleStorage([cnn.features[3]])x = torch.rand(1,3,224,224).requires_grad_(True).to(device) # random input, this can be an imageloss = nn.CrossEntropyLoss()# 1 is the ground truthoutput = loss(cnn(x), torch.tensor([1]))storage(output)# then we can use the layer to get the gradient out from itstorage[cnn.features[3]]
[(tensor([[[[ 1.6662e-05, 0.0000e+00, 9.1222e-06, ..., 1.2165e-07,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 1.8770e-05],[ 4.9425e-05, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],...,[ 7.3107e-05, 0.0000e+00, 0.0000e+00, ..., -2.6335e-05,0.0000e+00, 2.1168e-05],[ 1.0214e-07, 0.0000e+00, 8.3543e-06, ..., 0.0000e+00,8.6060e-06, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00]],[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 2.9192e-05,0.0000e+00, 0.0000e+00],[ 0.0000e+00, -1.3629e-05, 0.0000e+00, ..., 0.0000e+00,-8.7888e-06, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, -3.7738e-05, ..., 0.0000e+00,-3.6711e-05, 0.0000e+00],...,[ 0.0000e+00, 0.0000e+00, 4.7797e-05, ..., 0.0000e+00,-1.3995e-05, 0.0000e+00],[ 0.0000e+00, 3.2237e-05, 0.0000e+00, ..., 1.3353e-05,0.0000e+00, 2.6432e-05],[ 0.0000e+00, 0.0000e+00, -9.5113e-06, ..., 0.0000e+00,0.0000e+00, 0.0000e+00]],[[ 4.5919e-06, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., -1.2707e-05,0.0000e+00, 6.5265e-06],[ 3.4605e-05, 0.0000e+00, 0.0000e+00, ..., -2.7972e-06,0.0000e+00, -5.2525e-05],...,[ 0.0000e+00, 3.6611e-06, 6.0328e-06, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 9.9564e-07, ..., 2.1010e-05,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 1.1180e-05, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, -1.4692e-05]],...,[[ 0.0000e+00, 3.1771e-05, -2.2892e-05, ..., 0.0000e+00,0.0000e+00, 1.4811e-05],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],...,[ 5.0065e-06, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 4.7138e-05, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,-1.1021e-05, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00]],[[ 0.0000e+00, 0.0000e+00, 4.6386e-06, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[-9.7505e-06, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,-9.5954e-07, 0.0000e+00],[ 1.1188e-05, 0.0000e+00, 1.7352e-05, ..., 0.0000e+00,2.6517e-05, 0.0000e+00],...,[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[-2.7686e-06, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,1.7470e-05, 0.0000e+00]],[[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 1.3180e-06,2.5051e-05, 0.0000e+00],[ 0.0000e+00, 8.3131e-06, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, -2.1428e-05, ..., 0.0000e+00,-5.9600e-05, 0.0000e+00],...,[ 0.0000e+00, 2.1640e-05, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00],[ 0.0000e+00, 4.6622e-05, 0.0000e+00, ..., 0.0000e+00,-2.1942e-05, 0.0000e+00],[ 0.0000e+00, 0.0000e+00, 0.0000e+00, ..., 0.0000e+00,0.0000e+00, 0.0000e+00]]]]),)]