Chinese word segmentation, Part-of-speech tagging and Medical named entity recognition From scratch.
Chinese word segmentation, Part-of-speech tagging and Medical named entity recognition From scratch.
Dependencies:
# training, testing and evaluationpython3 run.py
Generate files:
Evaluation.md - markdown table of evaluation resultResult/ - prediction resultFinalResult/ - Final prediction result
├── Data => data set given by TA│ ├── devset│ ├── testset1│ └── trainset├── Evaluation => eval scripts given by TA|├── CWS => CWS model├── POS => POS tagging model├── NER => NER model|├── constant.py => some global constants and variables|├── dataset.py => data preprocessing├── model.py => high-level model API for all our model├── evaluate.py => high-level evaluation API└── run.py => the entire process
Data and scripts given by TA
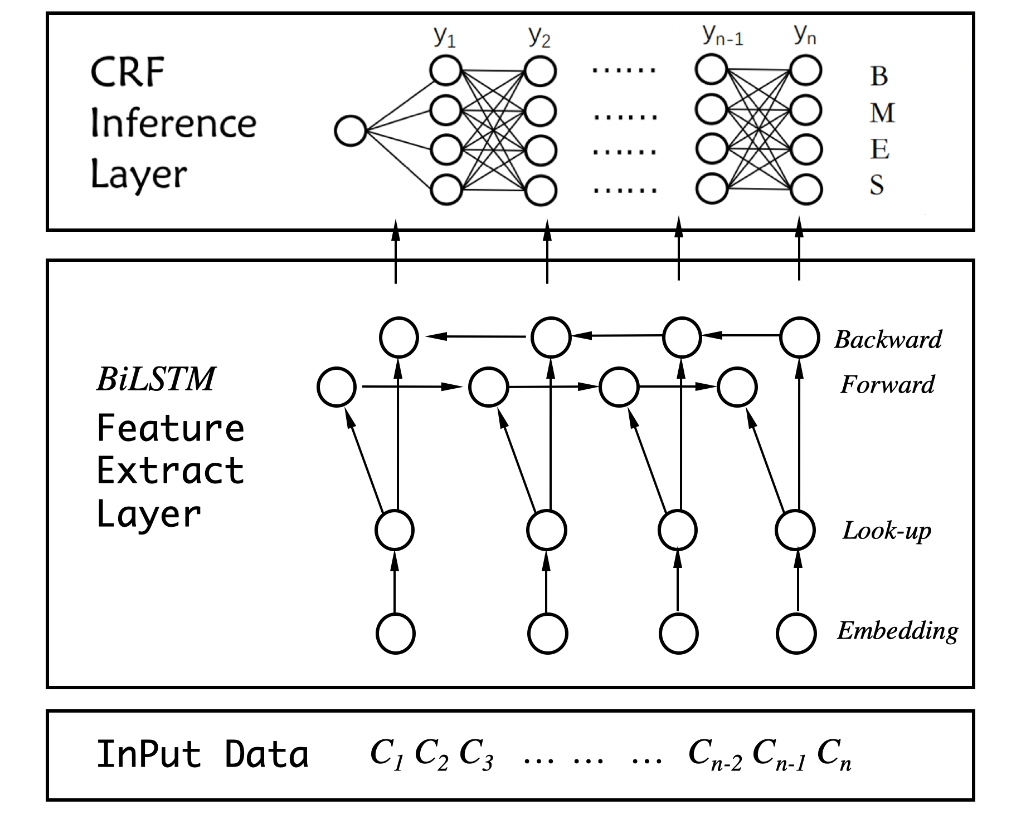
Sequence Tagging
Chinese Word Segmentation
Tools’ reference
pkuseg
@inproceedings{DBLP:conf/acl/SunWL12,author = {Xu Sun and Houfeng Wang and Wenjie Li},title = {Fast Online Training with Frequency-Adaptive Learning Rates for Chinese Word Segmentation and New Word Detection},booktitle = {The 50th Annual Meeting of the Association for Computational Linguistics, Proceedings of the Conference, July 8-14, 2012, Jeju Island, Korea- Volume 1: Long Papers},pages = {253--262},year = {2012}}