PyTorch code for JEREX: Joint Entity-Level Relation Extractor
PyTorch code for JEREX: “Joint Entity-Level Relation Extractor”. For a description of the model and experiments, see our paper “An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning”: https://arxiv.org/abs/2102.05980 (accepted at EACL 2021).
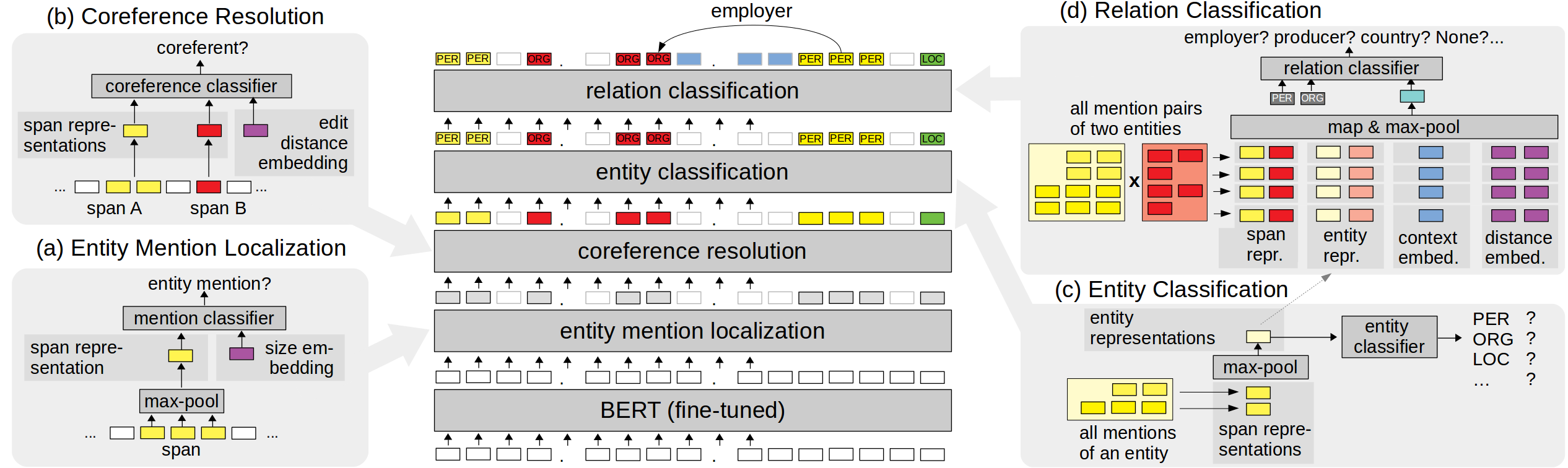
Execute the following steps before running the examples.
(1) Fetch end-to-end (joint) DocRED [1] dataset split. For the original DocRED split, see https://github.com/thunlp/DocRED :
bash ./scripts/fetch_datasets.sh
(2) Fetch model checkpoints (joint multi-instance model (end-to-end split) and relation classification multi-instance model (original split)):
bash ./scripts/fetch_models.sh
(1) Train JEREX (joint model) using the end-to-end split:
python ./jerex_train.py --config-path configs/docred_joint
(2) Evaluate JEREX (joint model) on the end-to-end split (you need to fetch the model first):
python ./jerex_test.py --config-path configs/docred_joint
To run these examples, first download the original DocRED dataset into ‘./data/datasets/docred/‘ (see ‘https://github.com/thunlp/DocRED‘ for instructions)
(1) Train JEREX (multi-instance relation classification component) using the orignal DocRED dataset.
python ./jerex_train.py --config-path configs/docred
(2) Evaluate JEREX (multi-instance relation classification component) on the original DocRED test set (you need to fetch the model first):
python ./jerex_test.py --config-path configs/docred
Since the original test set labels are hidden, the code will output an F1 score of 0. A ‘predictions.json’ file is saved, which can be used to retrieve test set metrics by uploading it to the DocRED CodaLab challenge (see https://github.com/thunlp/DocRED)
python ./jerex_train.py training.max_epochs=40
Performing a search over token spans (and pairs of spans) in the input document (as in JEREX) can be quite (CPU/GPU) memory demanding. If you run into memory issues (i.e. crashing of training/inference), these settings may help:
[1] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin,Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou,and Maosong Sun. 2019. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 764–777, Florence, Italy. ACL.