基于TF-IDF余弦相似度的地址语义搜索解析匹配服务
在文本相似度算法基础上加入语义处理,从已有历史地址库中搜索匹配相似地址。
片区划分在物流行业中比较重要,揽收、派送、运输路径规划、配车等核心作业都不同程度依赖片区规划。
传统解决方案一般重度依赖第三方GIS服务。受第三方服务本身、网络、通讯协议等诸多因素影响,性能、吞吐率、可用性瓶颈比较严重,尤其在双十一等高峰期。
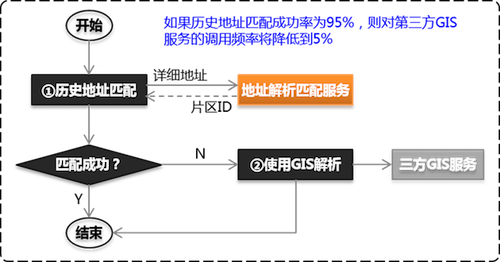
使用第三方GIS服务时的处理流程:
经纬度或平面坐标。经纬度或平面坐标。经纬度或平面坐标。物流公司在长期运营过程中积累了大量历史地址数据,其中包含了[地址]<<-->>[片区]对应关系,基于这些历史数据建立自己的地址匹配服务,可以降低第三方GIS的不利影响,节约费用。
本项目研究使用文本相似度,并加入语义处理,基于历史地址库进行地址解析和匹配。项目处于研究验证阶段,使用500万历史地址的情况下,匹配结果准确率比较高。
 \
\
先使用历史地址数据进行匹配,匹配不成功时再调用GIS服务解析。如果历史数据匹配成功率达到95%,则对GIS服务调用频率将降低到原来的5%。
项目中计算两个地址相似度借鉴了文本TF-IDF余弦相似度算法、Lucene的评分算法。
TF-IDF余弦相似度简单直观的说明可以参考TF-IDF与余弦相似性的应用(一):自动提取关键词、TF-IDF与余弦相似性的应用(二):找出相似文章。
TC: Term Count,词数,某个词在文档中出现的次数。TF: Term Frequency,词频,某个词在文档中出现的频率,TF = 该词在文档中出现的次数 / 该文档的总词数。IDF: Inverse Document Frequency,逆文档词频,IDF = log( 文档总数 / ( 包含该词的文档数 + 1 ) )。分母加1是为了防止分母出现0的情况。TF-IDF: 词条的特征值,TF-IDF = TF * IDF。 两个多维空间向量的余弦相似度: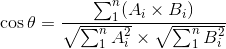
TF-IDF余弦相似度是比较通用、有效的文本相似度算法。其它文本相似度相关的算法有:最长公共子串、最长公共子序列、编辑距离、汉明距离等,基于语义的有LSA/LSI、PLSA、LDA等(参考既然LDA是一种比PLSA更高级的模型,为啥百度还在用PLSA?、CSDN专栏:主题模型 TopicModel)。
Elasticsearch: The Definitive Guide专门有一个章节比较详细地讲述了Lucene的评分算法:Theory Behind Relevance Scoring、Lucene’s Practical Scoring Function。

queryNorm(q) = 1 / sqrt( sumOfSquaredWeights ),sumOfSquaredWeights是查询文档q中每个词条的IDF平方根之和。同理,文档库中的每个文档也会使用这一公式进行归一化处理。queryNorm的目的是将lucene评分值进行归一化处理,使不同文档之间的评分值具有可比较性,但这个归一化算法严谨性有待证明。相比较之下,余弦相似度算法的结果无需额外的归一化处理。coord(q, d) = 文档d中匹配上的词条数量 / 文档q的词条数量 coord的效果是根据匹配词条数量进行加权,匹配词条越多加权值越高,表示查询文档q与文档d相关性越高,如果查询文档q的所有词条都能匹配,则coord值为1。2016_09中存放9月份的文档,索引2016_10中存放10月份的文档。Boost参数为相关性加权,可以为文档的不同Field设置不同的Boost,也可以为索引设置Boost(例如索引2016_10 Boost=2.0,索引2016_09 Boost=1.5)。norm(t, d) = 1 / sqrt( numTerms ),numTerms是文档d的词条数量。norm(t, d)是基于文档/Field长度进行的归一化处理,其效果是,同一个词条,出现在较短的Field(例如Title)中,比出现在较长的Field(例如Content)的相关性更高。TF-IDF的一些实际运用中会对TF使用这种方式进行计算,即TF = 该词在文档中出现的次数 / sqrt( 该文档的总词数 )地址相似度计算具有如下特点:
海淀区、万达广场不仅仅是一个词条,它们代表了区县、POI语义。...南京东路378号...,如果历史地址中不存在378号,但却有...南京东路380号...、...南京东路377号...,则这些地址的相似度非常高,道路名、门牌号语义并进行处理。
- 注意事项
- 1. 历史数据量的大小是影响精确度的重要因素
- 1.1 历史数据量越大,精确度越高。历史数据量小于一定程度,匹配结果的准确性会非常低。
- 1.2 目前精确到区县一级进行匹配,地址必须包含区县,且历史数据大小不能只看全国总量,需具体到每个区县。
- 1.3 POI的分布密度和片区的粗细粒度不同,对历史数据量的要求不一样。
- 例如农村地区POI密度低,片区划分粒度粗,仅需少量历史数据就能实现高精确度,但城市地区不行。
- 2. 边界地区精准度存在一定的不确定性
- 例如某条道路南面属于A区,北面属于B区,该道路上的地址匹配结果为A区还是B区存在不确定性。
- GIS同样无法实现100%精确,因为解析经纬度同样使用非结构化文本匹配方式。但GIS POI数据多,精确度相对较高。
- 3. 片区范围调整时需要保留出足够的学习积累期
- 例如某片区一分为二,或两片区合并的情况。
- 一个简单解决方案:如果结果落在该片区则认为无效,client重新从GIS得到片区ID,留出一段时间为该片区积累历史数据。
下载源码:
git clone https://github.com/liuzhibin-cn/address-similarity.git /your/src/path/
使用src/main/resources/conf/script/db-and-init-data.sql创建数据库和初始化省市区区域数据。
修改pom.xml文件,在profile节点test下面设置数据库连接信息。
执行maven命令编译打包(项目开发和测试环境使用的JDK1.8,项目使用的Dubbox也是在JDK1.8版本下源码编译的):
mvn clean package -P test
将生成的压缩包解压到运行目录:
mv target/address-match.tar.gz /your/dist/path/cd /your/dist/path/tar -xvzf address-match.tar.gz
运行demo服务需要先导入历史地址数据。
按照src/test/resources/test-addresses.txt的格式准备好历史数据文件。
执行下面命令将历史数据导入数据库:
bin/imp_address.sh /your/history/data/file/path
执行下面命令为全部地址计算词语特征值,并缓存到文件中:
bin/build_vector.sh
缓存目录通过pom.xml profile中的<cache.path></cache.path>节点进行设置,如果未设置,默认路径为~/.vector_cache/
运行下面命令启动demo服务:
bin/start.sh
停止服务使用bin/stop.sh。
服务启动成功后,通过http://localhost:8000/address/demo/find/北京海淀区丹棱街18号创富大厦1106?top=5访问。
Demo服务运行效果如下: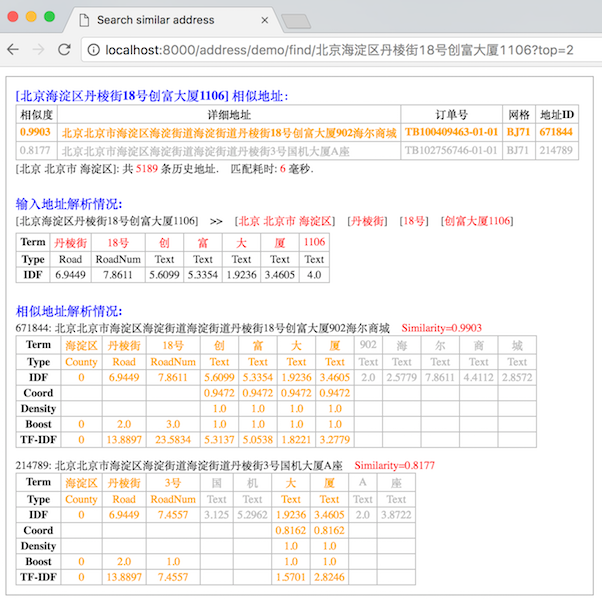
Demo服务使用的Dubbox的REST接口,服务启动时会监听2个端口:8080和8000。
如果需要修改为其他端口号,请修改以下文件:
spring-config.xml<dubbo:protocol name="rest" server="jetty" host="127.0.0.1" port="8000" contextpath="test"extension="com.alibaba.dubbo.rpc.protocol.rest.support.LoggingFilter" ></dubbo:protocol><dubbo:service interface="com.rrs.rd.address.demo.HttpDemoService" ref="demoService" register="false" protocol="rest" ></dubbo:service>
bin/start.shecho -e "Starting the service ...\c"nohup java -Ddubbo.spring.config=spring-config.xml -Ddubbo.jetty.port="8080" -Ddubbo.jetty.page=log,status,system -classpath $CONF_DIR:$CONF_DIR/dic:$LIB_JARS com.alibaba.dubbo.container.Main spring jetty > $DEPLOY_DIR/log/address-service-stdout.log 2>&1 &
倒排索引 Inverted Index匹配省市区。Done 20161018elasticsearch的评分算法。Done 20160925velocity生成demo service的html输出,输出分词等更详细信息,辅助分析准确率。Done 20160922AddressService中地址解析和数据持久化逻辑分离。Done 20160922TF-IDF算法,将词频TF改为对地址不同组成部分设置自定义权重。Dubbo更换为Dubbox,使用dubbox的REST API暴露HTTP测试验证接口;shell脚本,方便测试环境编译部署;