This composite pattern demonstrates a solution to a problem of Software Development domain using a combination of other individual code patterns.
The problem that we address in this pattern is in the domain of software development lifecycle. In the software development lifecycle, there are many artifacts that are generated - requirements, testcases, defects etc. In long running software projects with minimal tool support and a churn of team members, the new team members face many questions:
The composite pattern demonstrates a solution to this problem using a combination of other individual code patterns.
When the reader has completed this journey, they will understand how to:
The intended audience for this journey are developers who want to learn a method for building a solution with queryable insights on unstructured text content across documents. The distinguishing factor of this journey is that it allows a configurable mechanism to achieve the insights.
The pattern also demonstrates an interactive user interface using D3.js which allows an user to drill down to get more insights on the artifacts. D3.js is a JavaScript library for producing dynamic, interactive data visualizations in web browsers. It makes use of the widely implemented SVG, HTML5, and CSS standards.

IBM Watson Studio: Analyze data using RStudio, Jupyter, and Python in a configured, collaborative environment that includes IBM value-adds, such as managed Spark.
IBM Cloud Object Storage: An IBM Cloud service that provides an unstructured cloud data store to build and deliver cost effective apps and services with high reliability and fast speed to market.
Watson Natural Language Understanding: An IBM Cloud service that can analyze text to extract meta-data from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, semantic roles, using natural language understanding.
Node-RED: Node-RED is a programming tool for wiring together APIs and online services.
OrientDB: A Multi-Model Open Source NoSQL DBMS.
Kubernetes Clusters: an open-source system for automating deployment, scaling, and management of containerized applications.
Data Science: Systems and scientific methods to analyze structured and unstructured data in order to extract knowledge and insights.
Graph Database: A graph database is a database that uses graph structures for semantic queries with nodes, edges and properties to represent and store data. A key concept of the system is the graph (or edge or relationship), which directly relates data items in the store. The relationships allow data in the store to be linked together directly, and in many cases retrieved with one operation.
Follow these steps to setup and run this developer journey. The steps are
described in detail below.
Sign up for IBM’s Watson Studio. By creating a project in Watson Studio a free tier Object Storage service will be created in your IBM Cloud account
Create the IBM Cloud services required for the individual code patterns:
On the Node-RED flow editor, click the Menu and select Import -> Clipboard and paste the contents.

Deploy the Node-RED flow by clicking on the Deploy button


The websocket URL is ws://<NODERED_BASE_URL>/ws/orchestrate where the NODERED_BASE_URL is the marked portion of the URL in the above image.
An example websocket URL for a Node-RED app with name myApp is ws://myApp.mybluemix.net/ws/orchestrate, where myApp.mybluemix.net is the NODERED_BASE_URL.
The NODERED_BASE_URL may have additional region information i.e. eu-gb for the UK region. In this case NODERED_BASE_URL would be: myApp.eu-gb.mybluemix.net.
Click on the node named HTML.
Click on the HTML area and search for ws: to locate the line where the websocket URL is specified.
Update the websocket URL with the base URL that was noted in the Section 4:
var websocketURL = "ws://" + NODERED_BASE_URL + NODERED_websocket_path;

Click on Done and re-deploy the flow.
Deploy OrientDB on Kubernetes cluster using Deploy OrientDB on Kubernetes. It will expose the ports on IBM Cloud through which OrientDB can be accessed from the Jupyter notebook on IBM Watson Studio. Use the ip-address of your cluster and node port 2424 on which the OrientDB console is mapped, to access that OrientDB through Jupyter notebook.
Create notebook to create a notebook.From URL tab.Create button.
My Projects > Default page, Use Find and Add Data (look for the 10/01 icon)Files tab. browse and navigate to this repo engineering-insights-composite-pattern/data/sample_data.xlsxbrowse and navigate to this repo engineering-insights-composite-pattern/configuration/sample_config.txt
Note: It is possible to use your own data and configuration files.
If you use a configuration file from your computer, make sure to conform to the JSON structure given inconfiguration/sample_config.txt.
If you use your own data and configuration files, you will need to update the variables that refer to the data and configuration files in the Jupyter Notebook.
In the notebook, update the global variables in the cell following 6.1 Global Variables section.
Replace the values for dataFileName variable with the name of your data file and configFileName with your configuration file name.

The data for the different artifacts are on different sheets of the excel file. If you use your own naming convention for the excel sheet names, update the global variables in the cell following 6.1 Global Variables section in the notebook.
Replace the values for requirements_sheet_name,defects_sheet_name and testcases_sheet_name with the corresponding sheet names in the data excel file.
Select the cell below 2.1 Add your service credentials from Bluemix for the Watson services section in the notebook to update the credentials for Watson Natural Language Understanding.
Open the Watson Natural Language Understanding service in your IBM Cloud Dashboard and click on your service created in section Create IBM Cloud services.
Once the service is open, click the Service Credentials menu on the left.

In the Service Credentials that opens up in the UI, select whichever Credentials you would like to use in the notebook from the KEY NAME column. Click View credentials and copy username and password key values that appear on the UI in JSON format.

Update the username and password key values in the cell below 2.1 Add your service credentials from IBM Cloud for the Watson services section.

2.2 Add your service credentials for Object Storage section in the notebook to update the credentials for Object Store. Delete the contents of the cell
Use Find and Add Data (look for the 10/01 icon) and its Files tab. You should see the file names uploaded earlier. Make sure your active cell is the empty one below 2.2 Add...
Insert to code (below your sample_text.txt). Insert Credentials from drop down menu.credentials_1.
Connect to OrientDB under 5.2 OrientDB client - functions to connect, store and retrieve data, enter the hostname, port, username and password.
6. Expose integration point with a websocket client , update the websocket url noted in section 4 in the start_websocket_listener function.
When a notebook is executed, what is actually happening is that each code cell in
the notebook is executed, in order, from top to bottom.
IMPORTANT: The first time you run your notebook, you will need to install the necessary
packages in section 1.1 and thenRestart the kernel.
Each code cell is selectable and is preceded by a tag in the left margin. The tag
format is In [x]:. Depending on the state of the notebook, the x can be:
*, this indicates that the cell is currently executing.There are several ways to execute the code cells in your notebook:
Play button in the toolbar.Cell menu bar, there are several options available. For example, youRun All cells in your notebook, or you can Run All Below, that willSchedule button located in the top right section of your notebookThe UI can be accessed at the URL: http://<NODERED_BASE_URL>/engg-insights.
The <NODERED_BASE_URL> is the base URL noted in section Note the websocket URL.
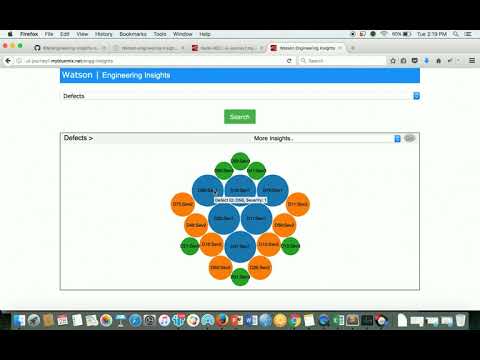
On the UI, you can get the list of defects, testcases or requirements.
Selecting Defects displays the list of all defects.

Clicking on a defect shows all the mapped testcases and requirements.

Similarly, for testcases - clicking on a testcase will display all the mapped requirements.
We can also get more insights like:
and so on.
Such insights can help in getting the related testcases and requirements for a defect that can help in testcase execution optimization.
The below image lists all the defects that have no associated testcases.

The solution can be enhanced through the following mechanisms.
Login can be misspelt as Logn. This text will not be tagged correctly. A spell correction can handle this scenario to provide better results.This code pattern is licensed under the Apache Software License, Version 2. Separate third party code objects invoked within this code pattern are licensed by their respective providers pursuant to their own separate licenses. Contributions are subject to the Developer Certificate of Origin, Version 1.1 (DCO) and the Apache Software License, Version 2.