An end-to-end machine learning and data mining framework on Hadoop
![]()

#
Please download latest shifu here.
After shifu downloading, build your first model with Shifu tutorial. More details about shifu can be found in our wiki pages.
Shifu is an open-source, end-to-end machine learning and data mining framework built on top of Hadoop. Shifu is designed for data scientists, simplifying the life-cycle of building machine learning models. While originally built for fraud modeling, Shifu is generalized for many other modeling domains.
One of Shifu’s pros is an end-to-end modeling pipeline in machine learning. With only configurations settings, a whole machine pipeline can be built and model can be much more easy to develop and push to production. The pipeline defined in Shifu is in below:
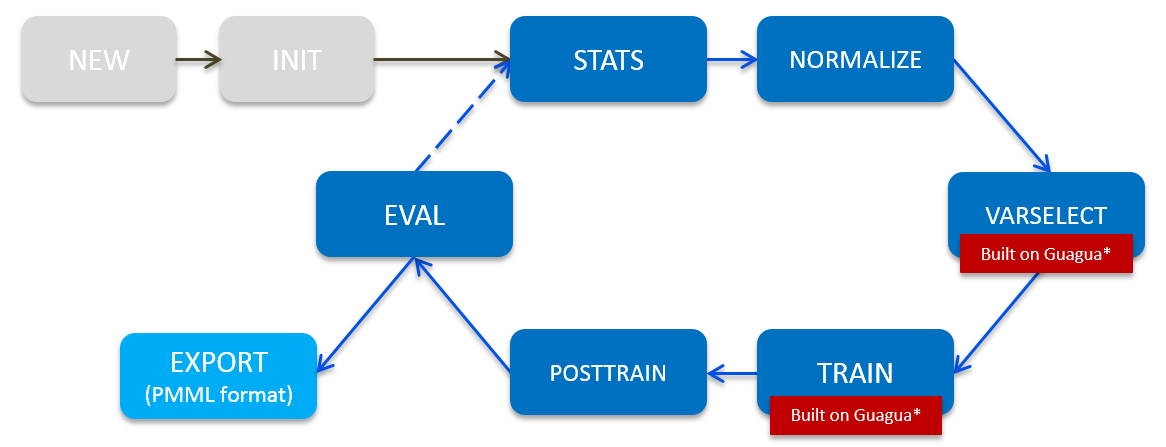
Shifu provides a simple command-line interface for each step of the model building process, including
Shifu’s fast Hadoop-based, distributed neural network / logistic regression / gradient boosted trees training can reduce model training time from days to hours on TB data sets. Shifu integrates with Pig workflows on Hadoop, and Shifu-trained models can be integrated into production code with a simple Java API. Shifu leverages Pig, Akka, Encog and other open source projects.
Guagua, an in-memory iterative computing framework on Hadoop YARN is developed as sub-project of Shifu to accelerate training progress.
More details about shifu can be found in our wiki pages
Please join Shifu group if questions, bugs or anything else.
Copyright 2012-2019, PayPal Software Foundation under the Apache License.