Create a ETL Pipeline for Data Modeling task with Python psycopg2
![]()
Create a ETL Pipeline for Data Modeling task with Python psycopg2
Report Bug
·
Request Feature
A startup called Sparkify wants to analyze the data they’ve been collecting on songs and user activity on their new music streaming app. The analytics team is particularly interested in understanding what songs users are listening to. Currently, they don’t have an easy way to query their data, which resides in a directory of JSON logs on user activity on the app, as well as a directory with JSON metadata on the songs in their app.
They’d like a data engineer to create a Postgres database with tables designed to optimize queries on song play analysis, and bring you on the project. Your role is to create a database schema and ETL pipeline for this analysis. You’ll be able to test your database and ETL pipeline by running queries given to you by the analytics team from Sparkify and compare your results with their expected results.
The first dataset is a subset of real data from the Million Song Dataset. Each file is in JSON format and contains metadata about a song and the artist of that song. The files are partitioned by the first three letters of each song’s track ID. For example, here are filepaths to two files in this dataset.
song_data/A/B/C/TRABCEI128F424C983.json
song_data/A/A/B/TRAABJL12903CDCF1A.json
And below is an example of what a single song file, TRAABJL12903CDCF1A.json, looks like.
{“num_songs”: 1, “artist_id”: “ARJIE2Y1187B994AB7”, “artist_latitude”: null, “artist_longitude”: null, “artist_location”: “”, “artist_name”: “Line Renaud”, “song_id”: “SOUPIRU12A6D4FA1E1”, “title”: “Der Kleine Dompfaff”, “duration”: 152.92036, “year”: 0}
The second dataset consists of log files in JSON format generated by this event simulator based on the songs in the dataset above. These simulate activity logs from a music streaming app based on specified configurations.
The log files in the dataset you’ll be working with are partitioned by year and month. For example, here are filepaths to two files in this dataset.
log_data/2018/11/2018-11-12-events.json
log_data/2018/11/2018-11-13-events.json
And below is an example of what the data in a log file, 2018-11-12-events.json, looks like.
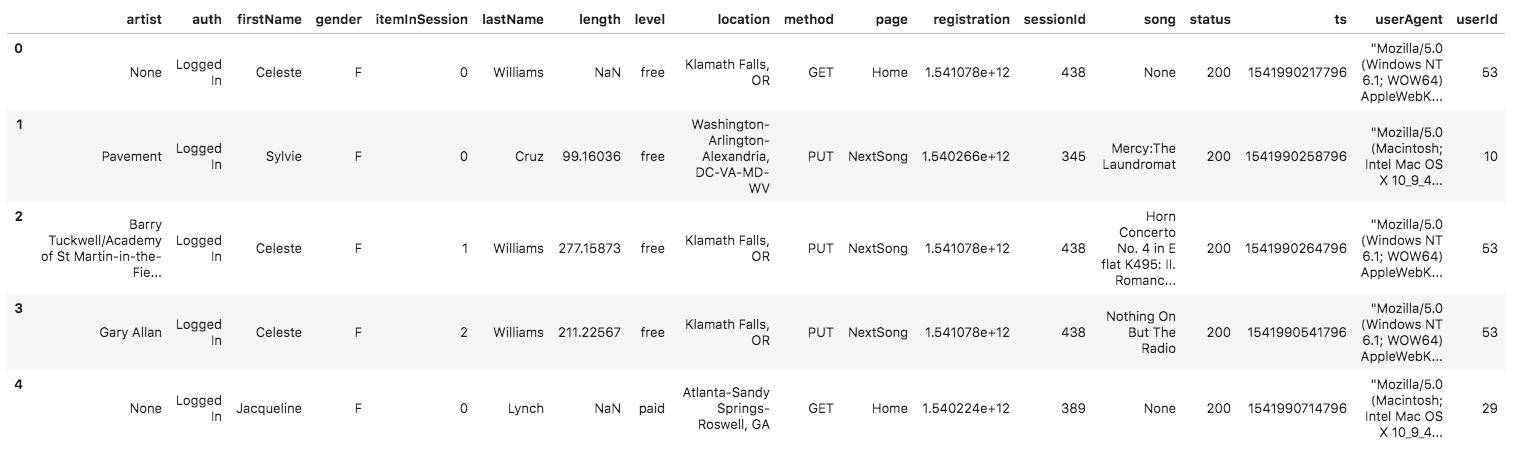
This is my database Star Schema.
install package with requirements.txt
Facebook - @Natchapol Patamawisut
Project Link: https://github.com/BankNatchapol/ETL-with-Python-psycopg2