Monitor performance, fairness, and quality of a WML model with AI OpenScale APIs
In this Code Pattern, we will use German Credit data to train, create, and deploy a machine learning model using Watson Machine Learning. We will create a data mart for this model with Watson OpenScale and configure OpenScale to monitor that deployment, and inject seven days’ worth of historical records and measurements for viewing in the OpenScale Insights dashboard.
When the reader has completed this Code Pattern, they will understand how to:

git clone https://github.com/IBM/monitor-wml-model-with-watson-openscalecd monitor-wml-model-with-watson-openscale
KEEP_MY_INTERNAL_POSTGRES = True remains unchanged.Databases for Postgres instance, follow these instructions:Note: Services created must be in the same region, and space, as your Watson Studio service.
Databases for Postgres service.Service Credentials tab on the left and then click New credential + to create the service credentials. Copy them or leave the tab open to use later in the notebook.
KEEP_MY_INTERNAL_POSTGRES = True
is changed to:
KEEP_MY_INTERNAL_POSTGRES = False
Create Watson OpenScale, either on the IBM Cloud or using your On-Premise Cloud Pak for Data.
 Click Start tour to tour the Watson OpenScale dashboard.
Click Start tour to tour the Watson OpenScale dashboard.Services section, click on the Instances menu option. Find the
Find the OpenScale-default instance from the instances table and click the three vertical dots to open the action menu, then click on the Open option.
Services section, click on the Instances menu option.
Find the OpenScale-default instance from the instances table and click the three vertical dots to open the action menu, then click on the Manage access option.
Add users button. For all of the user accounts, select the
For all of the user accounts, select the Editor role for each user and then click the Add button.
Under the Settings tab, scroll down to Associated services, click + Add service and choose Watson:

Search for Machine Learning, Verify this service is being created in the same space as the app in Step 1, and click Create.
Alternately, you can choose an existing Machine Learning instance and click on Select.
The Watson Machine Learning service is now listed as one of your Associated Services.
In a different browser tab go to https://cloud.ibm.com/ and log in to the Dashboard.
Click on your Watson Machine Learning instance under Services, click on Service credentials and then on View credentials to see the credentials.
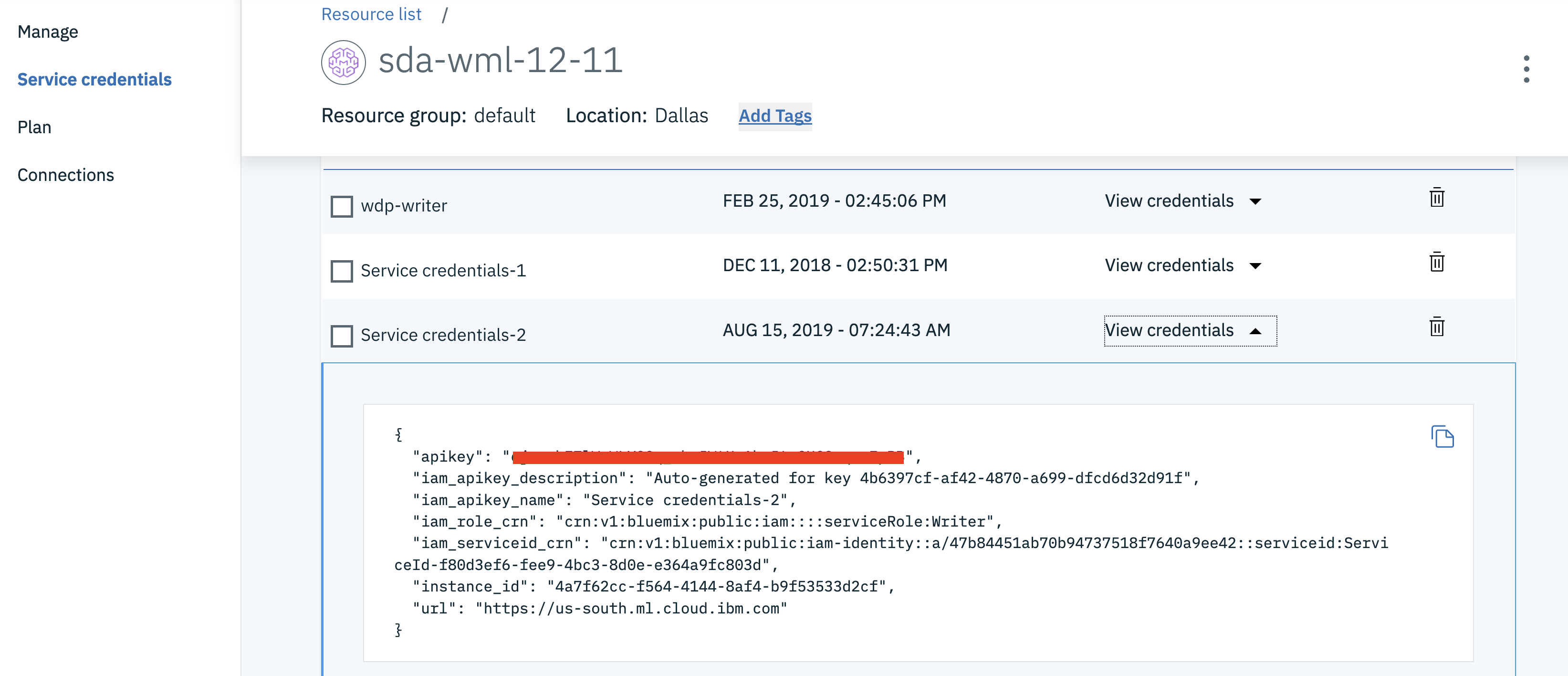
Save the credentials in a file. You will use them inside the notebook.
In Watson Studio or your on-premise Cloud Pak for Data, click New Project + under Projects or, at the top of the page click + New and choose the tile for Data Science and then Create Project.
Using the project you’ve created, click on + Add to project and then choose the Notebook tile, OR in the Assets tab under Notebooks choose + New notebook to create a notebook.
Select the From URL tab. [1]
Enter a name for the notebook. [2]
Optionally, enter a description for the notebook. [3]
For Runtime select the Default Spark Python 3.7 option. [4]
Under Notebook URL provide the following url: https://raw.githubusercontent.com/IBM/monitor-wml-model-with-watson-openscale/master/notebooks/WatsonOpenScaleMachineLearning.ipynb
Note: The current default (as of 8/11/2021) is Python 3.8. This will cause an error when installing the
pyspark.sql SparkSessionlibrary, so make sure that you are using Python 3.7
Create notebook button. [6]
Follow the instructions for Provision services and configure credentials:
Your Cloud API key can be generated by going to the Users section of the Cloud console.
From that page, click your name, scroll down to the API Keys section, and click Create an IBM Cloud API key.
Give your key a name and click Create, then copy the created key and paste it below.
Alternately, from the IBM Cloud CLI :
ibmcloud login --ssoibmcloud iam api-key-create 'my_key'
CLOUD_API_KEY in the cell 1.1 Cloud API key.In your IBM Cloud Object Storage instance, create a bucket with a globally unique name. The UI will let you know if there is a naming conflict. This will be used in cell 1.3.1 as BUCKET_NAME.
In your IBM Cloud Object Storage instance, get the Service Credentials for use as COS_API_KEY_ID, COS_RESOURCE_CRN, and COS_ENDPOINT:

Add the COS credentials in cell 1.2 Cloud object storage details.
Insert your BUCKET_NAME in the cell 1.2.1 Bucket name.
Either use the internal Database, which requires No Changes or Add your DB_CREDENTIALS after reading the instructions preceeding that cell and change the cell KEEP_MY_INTERNAL_POSTGRES = True to become KEEP_MY_INTERNAL_POSTGRES = False.
Move your cursor to each code cell and run the code in it. Read the comments for each cell to understand what the code is doing. Important when the code in a cell is still running, the label to the left changes to In [*]:.
Do not continue to the next cell until the code is finished running.
Now that you have created a machine learning model, you can utilize the OpenScale dashboard to gather insights.
You can find a sample notebook with output for WatsonOpenScaleMachineLearning-with-outputs.ipynb.
Insights tab to get an overview of your monitored deployments, Accuracy alerts, and Fairness alerts.
Spark German Risk Deployment and you can see tiles for the Fairness, Accuracy, and Performance monitors.


Explain icon on the left-hand menu and you’ll see a list of transactions that have been run using an algorithm to provide explainability. Choose one and click Explain.

Inspect tab and you can experiment with changing the values of various features to see how that would affect the outcome. Click the Run analysis button to see what changes would be required to change the outcome.